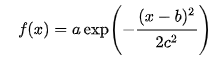이번 글에서는 저번 글에서 알아보았던 diffusion 모델 중 하나인 diff-svc를 직접 사용해보겠습니다. https://github.com/prophesier/diff-svc 이 링크의 자료들을 활용하였습니다. 이 모델을 이용하면 어느 사람의 말소리들로 다른 노래를 부르도록 만들 수 있습니다. 저는 쿤타라는 가수의 목소리로 뉴진스의 디토를 부르도록 만들어 볼건데요. 우선 쿤타라는 가수의 목소리를 얻어서 15초 단위로 끊어야 합니다. 데이터가 아주 많아야 결과가 좋긴 하지만 시간 관계상 조금의 데이터로 진행을 해보겠습니다. 보통 몇시간 정도의 데이터가 필요하지만 저는 고작 3분 정도로 해보겠습니다. ㅋㅋ 결과가 어떨지 궁금합니다. 오디오 파일들을 이런식으로 나눠서 준비해 주고요 이걸 압축해 줍니다...